Week 6 : Python Libraries for Data Science (Days 31-36)
1. Introduction
Most data-science curricula teach NumPy, Pandas, and EDA as separate notebooks. That works for concepts, but production teams do not ship six disconnected scripts—they ship one pipeline that loads data, validates it, transforms it, and produces artifacts other services can consume.
Week 6: Python Libraries for Data Science (Days 31–36) addresses that gap. Six daily lessons (NumPy foundations through a capstone EDA project) are integrated into a single repository: a core Python package, a composition engine, a FastAPI backend with dual API surfaces, and an optional React product UI.
The goal is not to replace the original day folders (they stay read-only as curriculum). The goal is to show how isolated lessons become composable modules behind stable HTTP contracts—exactly how backend engineers approach ML-adjacent systems.
2. System Overview
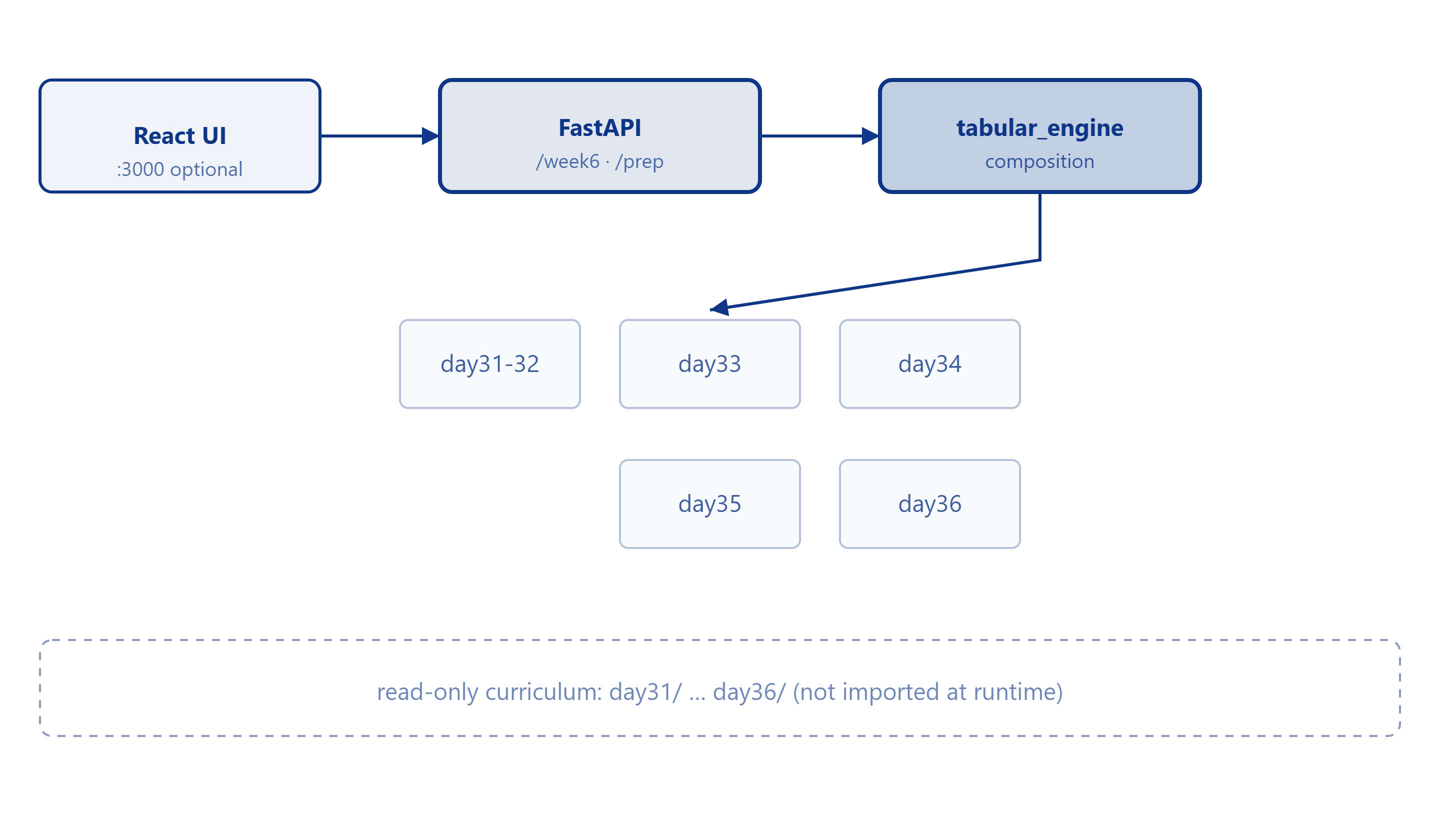
The integrated project (week_6_aiml_integrated_project) follows a four-layer layout:

Key components:
Core package (
week6_python): NumPy image prep, vectorization, Pandas I/O, DataFrame selection, missing-data cleaning, EDA engine.API layer:
/api/v1/week6/dayNN/*for teaching;/api/v1/prep/*for composed workflows.Composition engine (
tabular_engine):numpy_ops,pandas_io,selection,cleaning,eda,pipeline.Optional frontend: TabularPrep Studio—pipeline demo, CSV upload, step-by-step prep lab, architecture map.
Legacy Flask/Streamlit dashboards from individual days can run on ports 5101–5106 for comparison, but they are not part of the default product path.
3. Architecture Diagram