Day 76-84: Building Your First End-to-End ML System
What We’ll Build Today
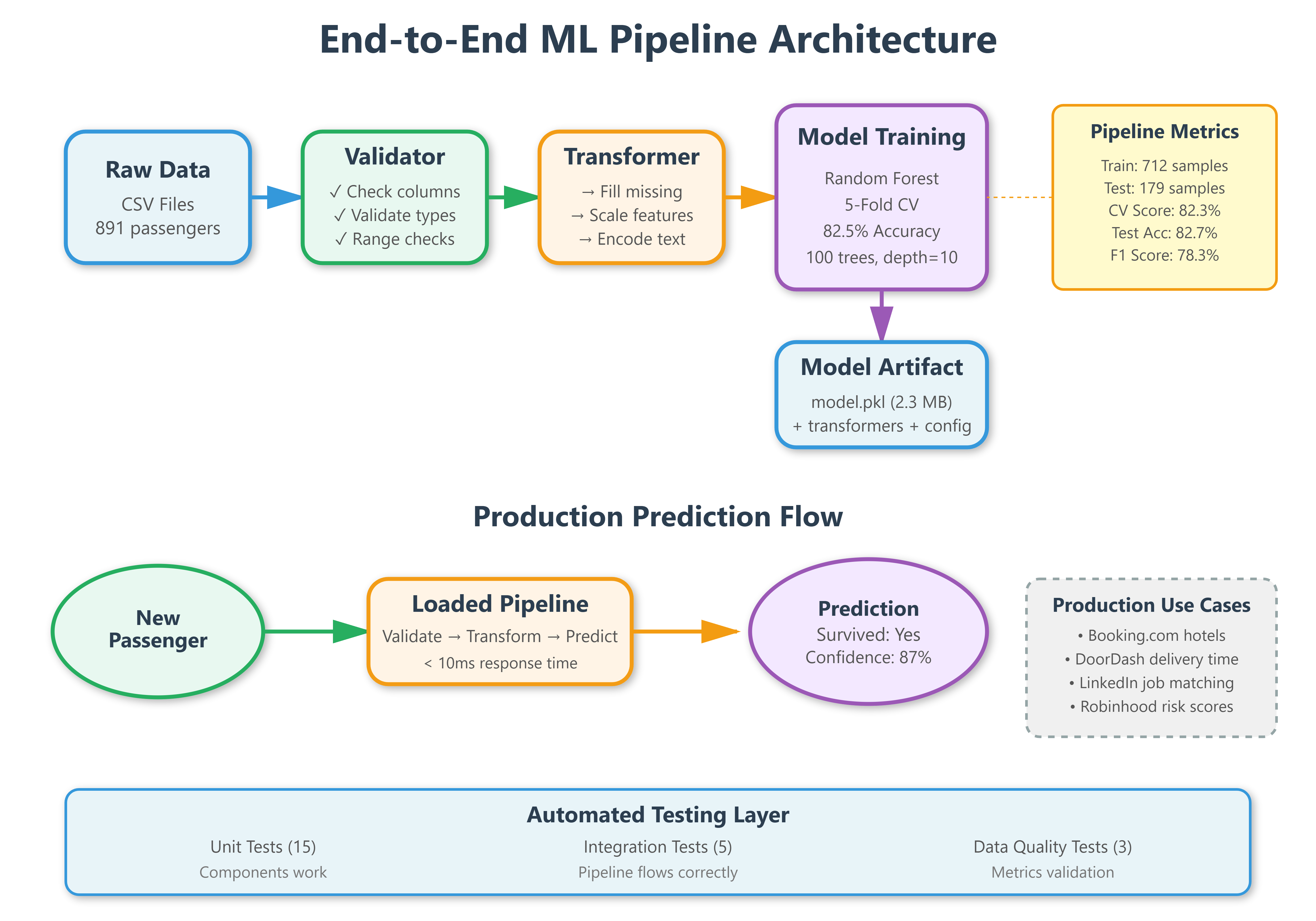
A complete production-ready ML pipeline from raw data to deployed model predictions
Automated data validation, feature engineering, and model training workflows
A simulation of how ML models serve predictions in real-time systems at companies like Booking.com, Airbnb, and LinkedIn
Why This Matters: From Notebooks to Production Systems
Every ML model you’ve seen powering products—Netflix’s recommendation engine, Uber’s surge pricing, Zillow’s home valuations—started as an experiment in a Jupyter notebook. But the gap between “my model works on my laptop” and “my model serves 10,000 predictions per second in production” is where most ML projects fail.
This lesson bridges that gap. You’ll build a complete system that mirrors how senior engineers at tech companies architect ML services: separating concerns, validating inputs, handling errors gracefully, and making your code testable and maintainable. The Titanic dataset is our vehicle, but the patterns you’ll learn apply to any supervised learning problem, from fraud detection at Stripe to content moderation at Discord.