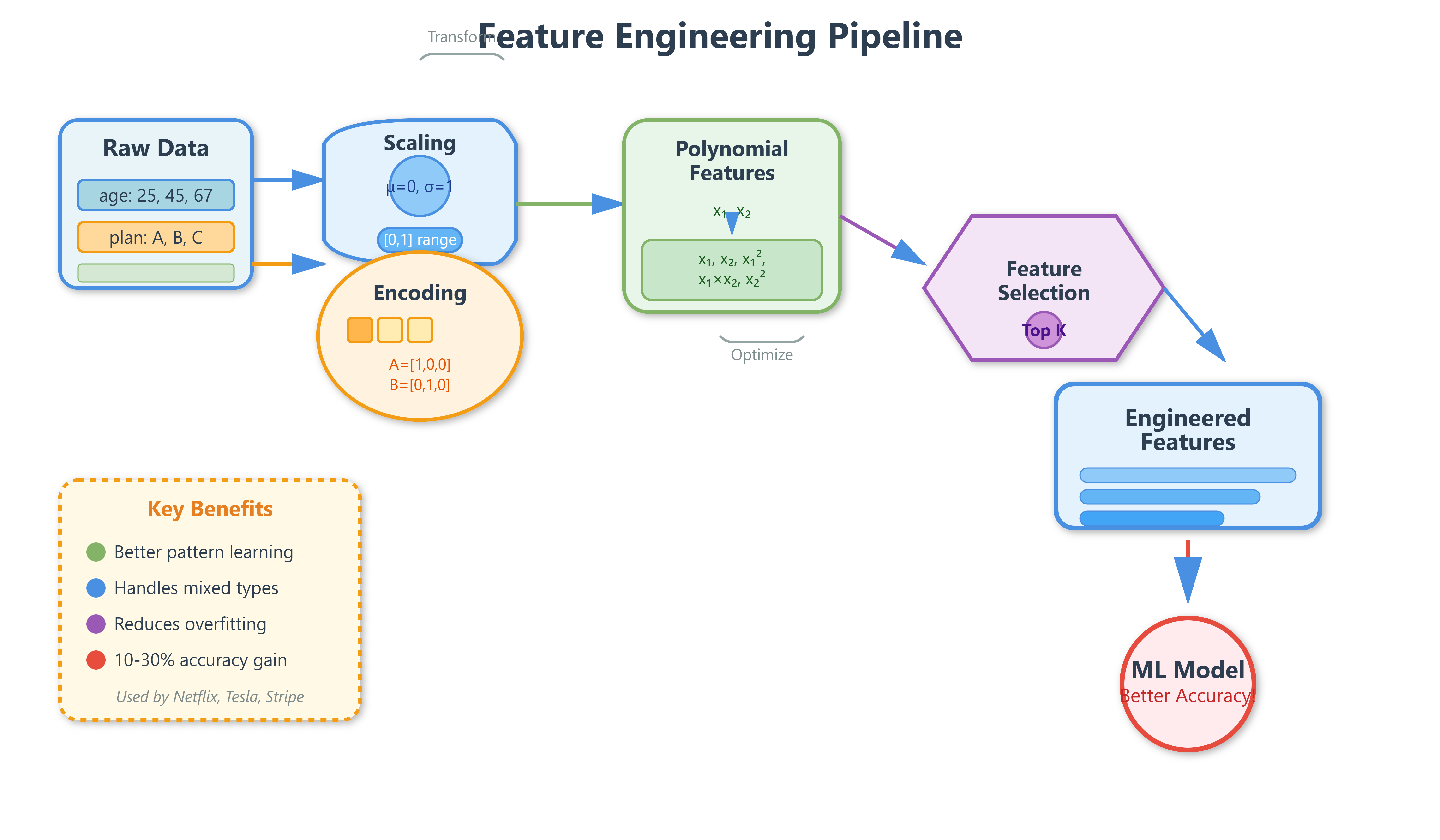
Day 74: Feature Engineering - The Art of Creating Predictive Power
What We’ll Build Today
Implement feature transformation techniques that mirror Netflix’s recommendation engine
Create polynomial features like Tesla uses for Autopilot trajectory prediction
Build categorical encoders similar to Stripe’s fraud detection system
Why This Matters: Raw Data Isn’t Ready for AI
Imagine you’re building a house price predictor. You have data: square footage, number of bedrooms, zip code. But here’s what separates junior from senior ML engineers: the raw data isn’t enough.
Netflix doesn’t just use “user clicked video” as a feature. They engineer hundreds of features: time since last watch, watch completion rate, genre preference score, time-of-day patterns. Tesla doesn’t feed raw camera pixels into Autopilot decision-making—they extract features like lane curvature, distance to obstacles, relative velocities.
Feature engineering is the process of transforming raw data into representations that make patterns easier for ML models to learn. It’s where 80% of a model’s performance improvement comes from in production systems. At Google, feature engineering teams are often larger than the teams building the actual models.
Core Concept: Turning Data Into Insights
1. Scaling and Normalization
Think of features as different measurement systems. Age ranges from 0-100, income from 0-1,000,000. Models like logistic regression and SVMs struggle when features are on wildly different scales—it’s like trying to compare centimeters to kilometers.
StandardScaler transforms features to have mean=0 and standard deviation=1. Spotify uses this for audio features where loudness (high values) shouldn’t dominate tempo (lower values) in their recommendation algorithm.
MinMaxScaler squashes values between 0 and 1. Amazon uses this for rating systems where they need bounded values for neural network inputs.
RobustScaler handles outliers gracefully. Financial fraud detection systems at Stripe use this because fraudulent transactions create extreme outliers that would break StandardScaler.