Day 72: Data Preprocessing and Feature Scaling
The Silent Performance Multiplier
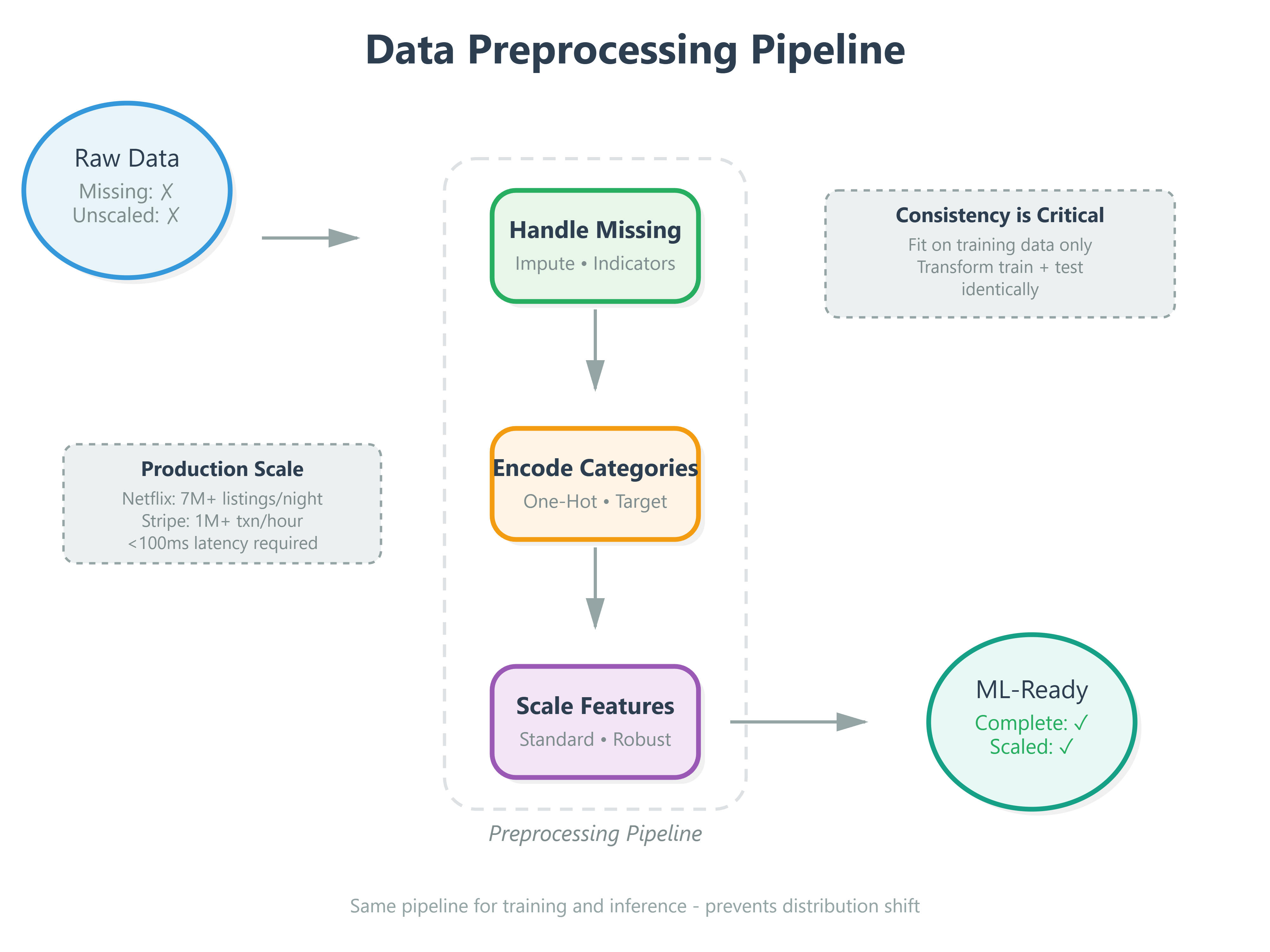
What We’ll Build Today
Real-time feature preprocessing pipeline that transforms raw user data into ML-ready format in under 50ms
Production-grade scaling system handling mixed data types (numerical, categorical, text)
Data quality validator that catches anomalies before they corrupt your models
Why This Matters: The $2 Million Bug That Could Have Been Prevented
In 2019, a recommendation system at a major streaming platform started suggesting horror movies to children’s accounts. The root cause? Feature scaling wasn’t applied consistently across their distributed pipeline. User age (range: 1-100) dominated the model while watch history features (range: 0-1) were effectively ignored. The fix took 3 hours. The PR damage? Months.
At Netflix, Spotify, and Amazon, data preprocessing isn’t a preprocessing step—it’s the difference between a model that works in Jupyter and one that survives production. When Tesla’s Autopilot processes camera feeds at 36 frames per second, each pixel value must be normalized identically across training and inference. A single inconsistent preprocessing step means your model sees different “versions” of reality.
Here’s what separates hobbyist ML from production AI: preprocessing consistency. Your model’s accuracy in production is bounded by your preprocessing pipeline’s reliability, not your algorithm choice.
Core Concept 1: The Three Preprocessing Problems That Break Production Models
Missing Data - The Silent Model Killer
When Google’s ad recommendation system encounters a missing feature (user didn’t provide age, incomplete profile), it doesn’t crash—it has a strategy. Three approaches exist:
Imputation - Replace missing values with statistical estimates. Mean imputation (average) works for normally distributed features. Median handles outliers better. Mode works for categorical data. The key insight: your imputation strategy must match your data distribution, or you’re injecting systematic bias.
Indicator variables - Create a binary “was_missing” flag. Why? Sometimes missingness itself is predictive. Users who don’t share their age might behave differently. LinkedIn’s recommendation system uses this pattern extensively.
Deletion - Remove samples with missing data. Only viable when less than 5% of data is affected and missingness is truly random (rare in real systems).
Production pattern: Spotify’s recommendation engine uses a hybrid approach—impute numerical features with median, create indicators for high-value features, and maintain separate models for cold-start users (lots of missing data) vs. established users.