Day 43: Model Evaluation Metrics
Accuracy, Precision, and Recall
What We’ll Build Today
Implement accuracy, precision, and recall calculators from scratch
Build a metrics dashboard that reveals hidden model failures
Understand why accuracy can lie and when it’s dangerous to trust it
Why This Matters: The $8 Million Mistake
In 2019, a major hospital network deployed an AI system to predict patient readmissions with 95% accuracy. Impressive, right? Wrong. The model was marking only 2% of patients as high-risk when 8% actually needed intensive care. Those 6% of missed cases cost the hospital $8M in emergency readmissions and nearly resulted in several preventable deaths.
The problem? They optimized for accuracy when they should have optimized for recall. In healthcare, missing a sick patient (false negative) is catastrophically worse than over-cautious predictions (false positive). The hospital learned an expensive lesson: different problems need different metrics.
This isn’t unique to healthcare. Google’s spam filter prioritizes precision (don’t mark good emails as spam) over recall (catch every spam email). Tesla’s autopilot does the opposite for pedestrian detection—missing a pedestrian is unacceptable, so they tolerate more false alarms. Meta’s content moderation balances both because false positives (removing good content) and false negatives (leaving harmful content) both damage the platform.
Today, you’ll learn to choose the right metric for the right problem—a skill that separates junior developers from production AI engineers.
Core Concepts: The Three Pillars of Classification
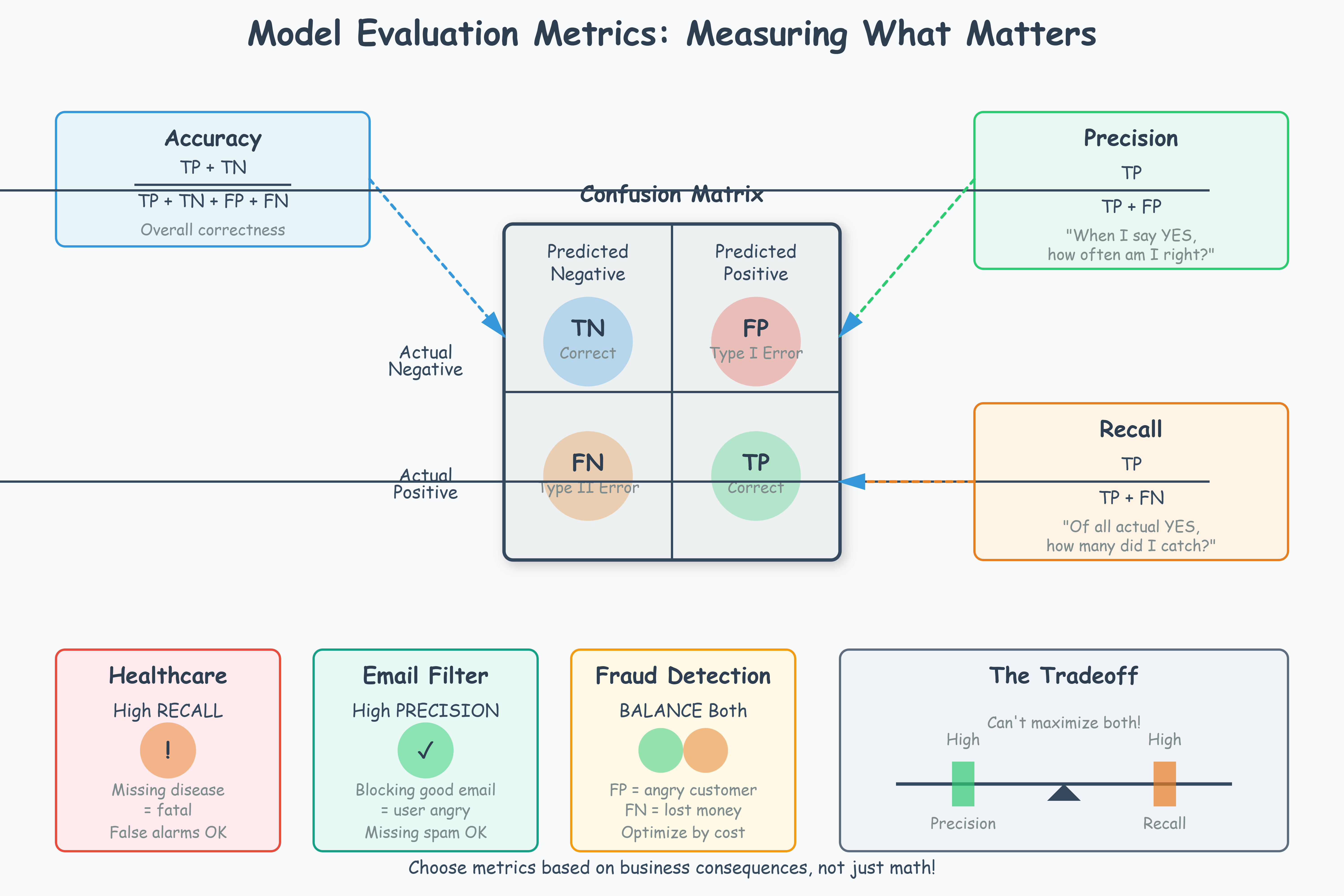
Accuracy: The Beautiful Liar
Accuracy seems obvious: what percentage of predictions were correct? But here’s where it becomes dangerous.
Imagine you’re building fraud detection for a payment processor. Out of 10,000 transactions, only 50 are fraudulent (0.5%). A lazy model that marks everything as “legitimate” achieves 99.5% accuracy while catching zero fraud. Perfect accuracy, complete failure.
When accuracy works: Balanced datasets where all classes matter equally. Netflix’s recommendation system (users either like or dislike content roughly 50/50) relies heavily on accuracy because both false positives and negatives equally hurt user experience.
When accuracy fails: Imbalanced datasets (fraud detection, disease diagnosis, equipment failure prediction) where the minority class is actually what you care about most.
Precision: The Trust Builder
Precision answers: “When my model says YES, how often is it actually YES?”
Precision = True Positives / (True Positives + False Positives)
Think about Google Search. When you type “best coffee shops near me,” precision means the top results are actually good coffee shops. If Google shows you 10 results and 9 are excellent but 1 is a tire shop, that’s 90% precision. Low precision erodes user trust fast—one bad result makes users question all future searches.
Critical for: Systems where false positives are expensive or annoying. Spam filters (marking legitimate emails as spam frustrates users), legal e-discovery (flagging irrelevant documents wastes lawyer time at $500/hour), targeted advertising (showing irrelevant ads wastes budget and annoys users).
OpenAI’s ChatGPT moderation: Prioritizes precision because falsely blocking a safe user query (false positive) creates PR disasters and user frustration. They’d rather let some edge cases through than over-moderate.
Recall: The Safety Net
Recall answers: “Of all the actual YES cases, how many did I catch?”
Recall = True Positives / (True Positives + False Negatives)
Tesla’s pedestrian detection system runs at near-100% recall. It will flag shadows, plastic bags, and wind-blown leaves as potential pedestrians. The car might brake unnecessarily, but it will never miss an actual person. Missing one pedestrian (false negative) is infinitely worse than 100 false alarms.
Critical for: Systems where false negatives are dangerous or costly. Security threat detection (missing one attack can breach the entire system), medical diagnosis (missing cancer is fatal), credit card fraud (missing fraud costs the bank money).
Meta’s harmful content detection: Optimizes for recall because missing harmful content (false negatives) creates legal liability and user safety issues. They accept higher false positive rates (accidentally removing borderline content) as the cost of catching dangerous material.
The Precision-Recall Tradeoff
Here’s the cruel reality: you can’t maximize both simultaneously. It’s a seesaw.
Increase precision → You become more conservative, flagging only things you’re absolutely certain about → You miss more true cases (lower recall)
Increase recall → You become more aggressive, flagging anything suspicious → You create more false alarms (lower precision)
Real example from Stripe’s fraud detection:
High precision mode (99% precision, 65% recall): Blocks only obvious fraud, misses 35% of fraudulent transactions but rarely blocks legitimate customers
High recall mode (75% precision, 98% recall): Catches almost all fraud but blocks 25% more legitimate transactions, creating customer service nightmares
Stripe actually runs multiple models with different thresholds and routes transactions based on risk scores, letting merchants choose their preferred tradeoff.