What We’ll Build Today
Today you’re building a production-ready data cleaning pipeline that handles real-world messy data. This isn’t toy code—it’s the same approach Netflix uses to clean 200+ billion events daily. You’ll create automated missing data detection, implement multiple imputation strategies, and build a tool that actually works at scale.
Why This Matters: The Hidden 80% of AI Work
Here’s what nobody tells you about AI engineering: you’ll spend 80% of your time cleaning data, not training models. When Tesla’s Autopilot receives sensor data, 30% of readings are corrupted or missing. When Netflix analyzes user behavior, millions of events have incomplete information. When Google trains recommendation systems, entire columns of data are mysteriously blank.
Every production AI system at every major tech company has one thing in common: a bulletproof data cleaning pipeline that runs before any model sees the data. Master this, and you’ve mastered what separates working AI systems from academic exercises.
The difference between a model that works in a notebook and one that runs in production isn’t the algorithm—it’s how you handle the messy, incomplete, contradictory data that exists in every real-world system.
Core Concept 1: Why Data Gets Dirty (And Why It Matters)
Real-world data is never clean. Ever. Here’s why:
User behavior is unpredictable. Someone fills out 60% of a form, gets distracted, and submits anyway. Spotify has millions of user profiles missing age, gender, or location data because users skip optional fields.
Systems fail. Sensors break mid-collection. Network requests timeout halfway through. Tesla’s cameras occasionally produce corrupted frames when sunlight hits at extreme angles. That’s not a bug—it’s physics meeting reality.
Integration creates gaps. When Netflix merges viewing data from mobile apps, smart TVs, and web browsers, timestamps don’t always align. Data types conflict. Fields that exist in one system are absent in another.
Human error is constant. Typos, wrong units (mixing feet and meters), impossible dates (February 30th), negative ages. Your pipeline must handle all of it gracefully.
In production AI systems, missing data isn’t an edge case—it’s the default state. Google’s advertising models process billions of events daily where 40-50% have some missing fields. The system still works because the cleaning pipeline is robust.
Core Concept 2: The Three Types of Missing Data
Not all missing data is equal. Understanding the type determines your strategy:
Missing Completely at Random (MCAR). The missingness has no pattern. A survey response is missing because someone’s internet cut out during submission. You can safely delete these rows or impute without introducing bias. This is rare in real systems.
Missing at Random (MAR). The missingness relates to observed data, not the missing value itself. Example: older users are less likely to provide phone numbers on social media. Netflix sees this: users who watch on smart TVs are less likely to complete profile information than mobile users. You can’t delete these rows—you’d lose entire demographics. You must impute intelligently.
Missing Not at Random (MNAR). The missingness relates to the missing value itself. High-income earners intentionally skip salary questions. Failed sensors produce no readings specifically during extreme conditions when readings matter most. This is the dangerous case—naive imputation introduces systematic bias. Tesla’s Autopilot specifically trained to detect when camera failures correlate with dangerous driving conditions.
OpenAI’s content moderation systems see MNAR constantly: the most toxic content is most likely to have missing metadata because users intentionally obscure information when posting harmful content. The missing data itself is the signal.
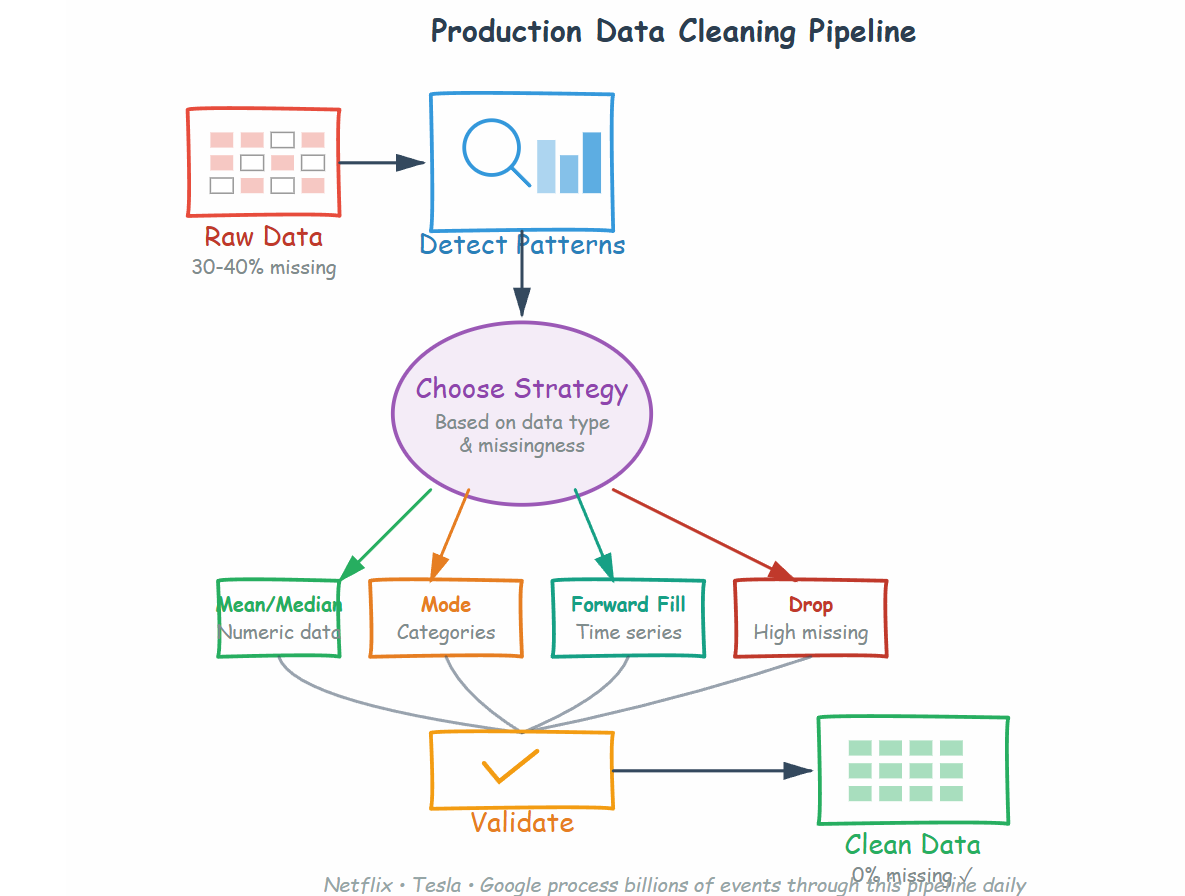
Core Concept 3: Professional Imputation Strategies
Here’s how production systems handle missing data:
Mean/Median/Mode Imputation (The Fast Default). Replace missing numbers with column average. Replace missing categories with most common value. Netflix uses this for non-critical features like “time to first pause” in viewing sessions. Fast, simple, good enough when the feature isn’t crucial.
Forward Fill / Backward Fill (Time Series Gold Standard). Carry the last known value forward or pull the next value backward. Tesla uses this extensively—if a sensor reading is missing for 100ms, use the previous reading. Google’s stock price models do this constantly. Only works for sequential data.
KNN Imputation (The Smart Approach). Find the 5 most similar rows and use their average. Spotify uses this: if a user’s age is missing, find 5 users with similar listening patterns and use their average age. This preserves relationships in your data. Computationally expensive at scale—Netflix processes this on Spark clusters, not single machines.
Model-Based Imputation (The Nuclear Option). Train a model to predict the missing values. Google does this for critical features in ad ranking—if click-through-rate data is missing, predict it using a separate model trained on historical patterns. Only for high-value features where accuracy matters more than speed.
Drop Strategy (The Underrated Choice). Sometimes deleting rows or columns is correct. If 95% of a column is missing, that column provides no information—drop it. If 1% of rows have missing target variables in a classification problem, those rows are useless—drop them. Production systems at scale can afford to lose 5-10% of data if it improves model accuracy.