Day 16-22: Linear Algebra & Calculus Review
Building Your Math Foundation for AI

What We’ll Master This Week
Solidify vector and matrix operations that power every neural network
Practice gradient calculations that teach AI systems to learn
Connect mathematical concepts to real AI applications you’ll build
Why This Mathematical Foundation Matters
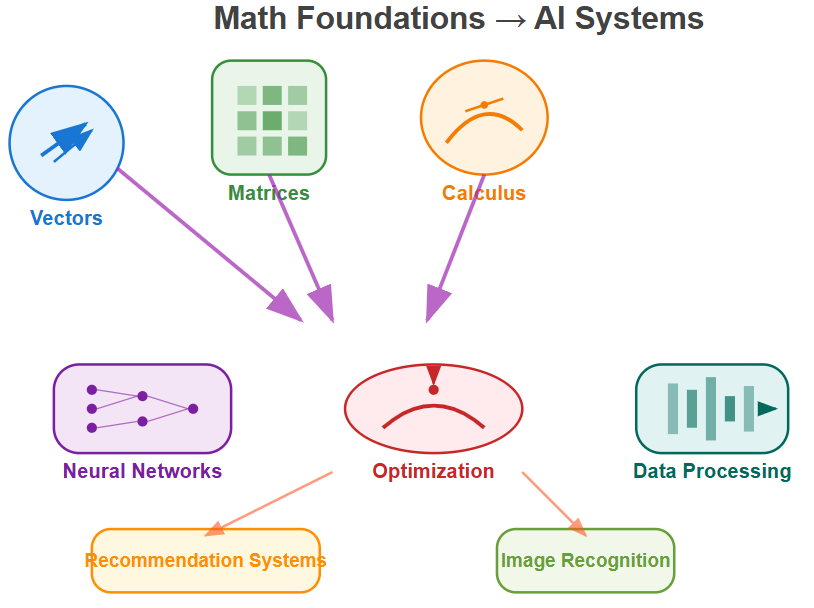
Think of linear algebra and calculus as the language that AI systems use to understand the world. When ChatGPT processes your question, it’s manipulating millions of vectors and matrices behind the scenes. When a self-driving car recognizes a stop sign, it’s using derivatives to optimize its neural network. This week isn’t about memorizing formulas—it’s about building the mathematical intuition that will make advanced AI concepts feel natural.
Every gradient descent step, every neural network layer, every optimization algorithm relies on the concepts we’re reviewing. Master these fundamentals now, and you’ll understand AI at a deeper level than most practitioners who treat it as a black box.
Core Mathematical Concepts for AI
1. Vectors: The Building Blocks of AI Data
In AI, everything is a vector. A word becomes a vector of numbers, an image becomes a vector of pixel values, and user preferences become vectors of ratings. Understanding vector operations isn’t just math—it’s understanding how AI thinks.
Key Operations to Master:
Dot product: Measures similarity between data points
Vector addition: Combines information from multiple sources
Scalar multiplication: Adjusts the strength of signals
Vector magnitude: Determines the importance of features
Think of recommendation systems: when Netflix suggests a movie, it’s calculating dot products between your preference vector and movie feature vectors. The highest dot product wins your Friday night.
2. Matrices: Organizing AI Transformations
If vectors are data points, matrices are transformations. Every layer in a neural network is essentially a matrix that transforms input data into something more useful. When you rotate an image for data augmentation, you’re applying matrix multiplication.
Essential Matrix Operations:
Matrix multiplication: How neural networks process information layer by layer
Transpose: Flipping data to match different processing requirements
Inverse: Solving systems of equations in optimization problems
Eigenvalues/eigenvectors: Finding the most important directions in data
3. Derivatives: How AI Systems Learn
Here’s where the magic happens. Derivatives tell us how changing one thing affects another. In AI, we use derivatives to figure out which direction to adjust our model’s parameters to make better predictions.
Critical Derivative Concepts:
Partial derivatives: How changing one parameter affects the output
Chain rule: How errors propagate backwards through neural networks
Gradient: The direction of steepest increase (or decrease) in our loss function
Critical points: Where our AI model performs optimally
4. Gradient Descent: The Learning Algorithm
Imagine you’re hiking in fog and trying to reach the lowest point in a valley. You can only feel the slope under your feet. Gradient descent is exactly this—an AI system feeling the slope of its error function and taking steps downhill toward better performance.
This is how every AI model learns: calculate the gradient (which way is downhill), take a step in that direction, repeat until you reach the bottom (optimal performance).
Implementation: Mathematical Practice Problems
Problem Set 1: Vector Operations for Similarity Matching
import numpy as np
# User preference vectors (like Netflix recommendations)
user_a = np.array([4.2, 3.8, 2.1, 4.9, 1.3]) # Action, Comedy, Drama, Sci-fi, Horror
user_b = np.array([4.1, 3.9, 2.3, 4.7, 1.1])
# Calculate similarity using dot product
similarity = np.dot(user_a, user_b)
print(f”User similarity: {similarity}”)
# Practice: Normalize vectors first for better comparison
def cosine_similarity(vec1, vec2):
return np.dot(vec1, vec2) / (np.linalg.norm(vec1) * np.linalg.norm(vec2))
Problem Set 2: Matrix Operations for Data Transformation
# Simulate a simple neural network layer
input_data = np.array([[1.0, 2.0, 3.0]]) # One data sample with 3 features
weights = np.array([[0.1, 0.2], [0.3, 0.4], [0.5, 0.6]]) # 3 inputs to 2 outputs
bias = np.array([[0.1, 0.1]])
# Forward pass: input * weights + bias
output = np.dot(input_data, weights) + bias
print(f”Neural network output: {output}”)
Problem Set 3: Gradient Calculations for Optimization
# Simple quadratic function: f(x) = x^2 + 3x + 2
def f(x):
return x**2 + 3*x + 2
# Its derivative: f’(x) = 2x + 3
def f_prime(x):
return 2*x + 3
# Gradient descent to find minimum
x = 5.0 # Starting point
learning_rate = 0.1
for step in range(10):
gradient = f_prime(x)
x = x - learning_rate * gradient
print(f”Step {step}: x={x:.3f}, f(x)={f(x):.3f}”)
Real-World Connection: Where You’ll See This in Production AI
Computer Vision: Convolutional neural networks use matrix convolutions to detect edges, shapes, and objects in images. Every Instagram filter is applied through matrix operations.
Natural Language Processing: Word embeddings are high-dimensional vectors, and transformer models (like GPT) use matrix attention mechanisms to understand context and relationships between words.
Recommendation Systems: Companies like Amazon and Spotify use vector similarity and matrix factorization to predict what products or songs you’ll enjoy next.
Optimization Everywhere: From training large language models to optimizing ad targeting, gradient descent and its variants (Adam, RMSprop) are the workhorses that make AI systems continuously improve.