Today’s Agenda
Run a complete Keras training loop on MNIST from scratch
Configure loss functions, optimizers, and metrics for production-grade models
Add callbacks that stop wasted training automatically
Evaluate model performance and interpret validation results like an engineer
Save a deployable model artifact to disk
Why This Matters
Every AI product you will ever build — a recommendation engine, a fraud detector, a medical image classifier — has a training pipeline at its core. That pipeline is not magic. It is a structured loop that feeds data forward through the network, measures how wrong the output is, and nudges every weight slightly in the right direction.
Keras wraps that loop cleanly, but the engineer still has to make deliberate decisions about what “wrong” means (loss), how fast to correct it (optimizer), and whether the model is generalizing or just memorizing (validation). Getting those three things right is what separates a model that ships from one that sits in a notebook forever.
Core Concepts
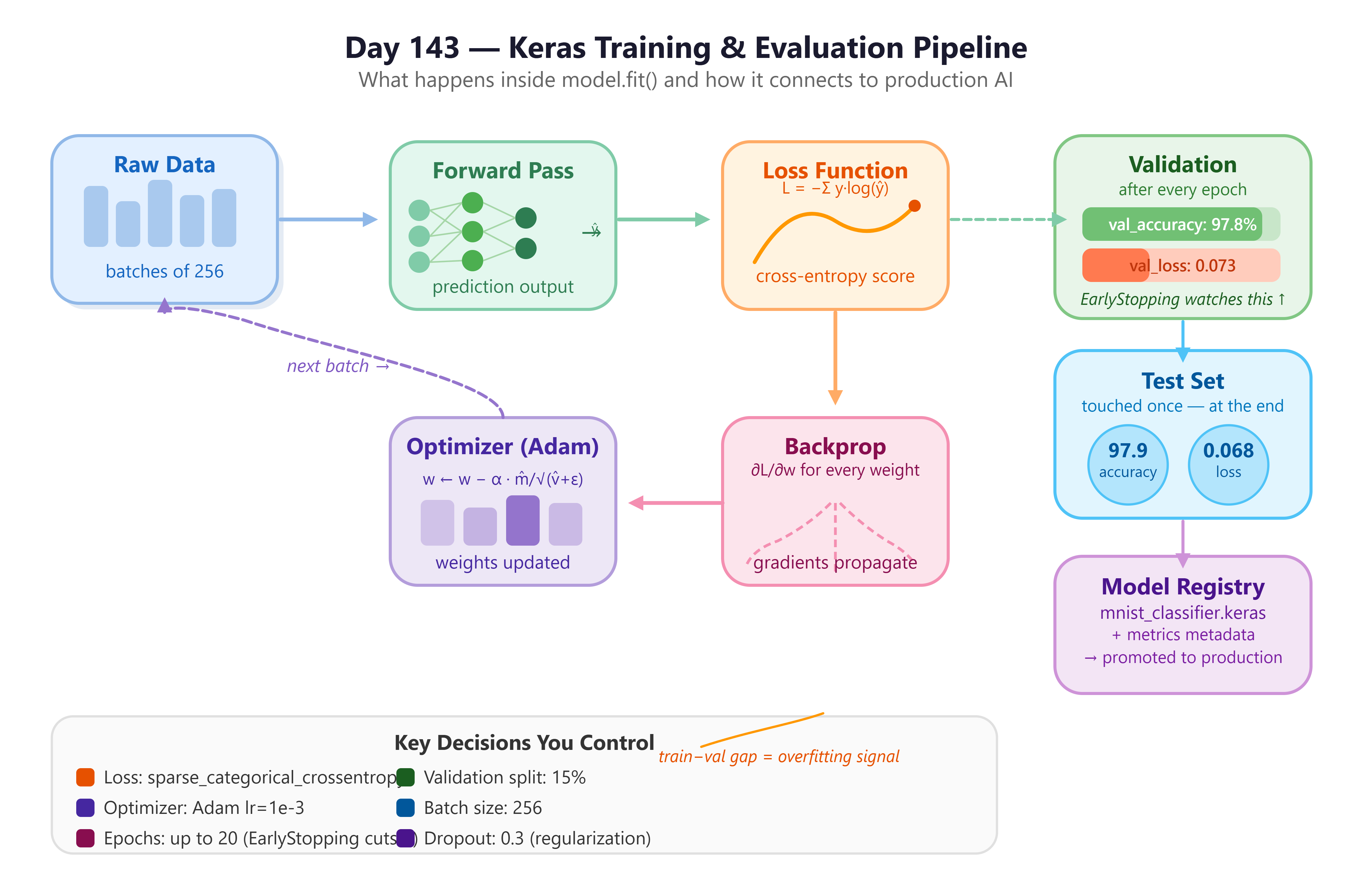
1. The Training Loop: What Actually Happens
When you call model.fit(), Keras executes a precise four-step sequence for every single batch of data:

This four-step sequence repeats for every batch. One full pass through all the training data is called an epoch. The number of epochs is yours to control. Too few and the model under-learns. Too many and it memorizes the training data and fails on anything slightly different — a problem called overfitting.
Key Insight: Think of epochs like studying for an exam. Reading your notes once leaves gaps. Memorizing last year’s exact questions means you fail any question that is slightly different.
2. Loss Functions: Defining “Wrong”
The loss function is the mathematical definition of what it means for a prediction to be incorrect. The choice is not arbitrary — it depends entirely on the type of problem you are solving.
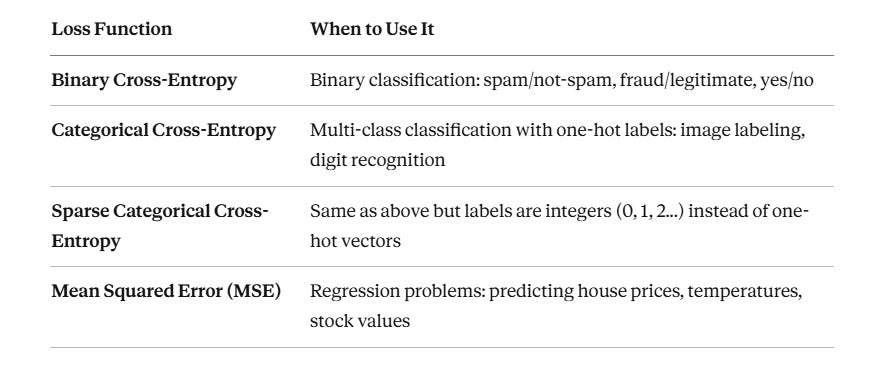
In production AI systems, loss functions are sometimes custom-designed. OpenAI’s RLHF pipeline uses a reward-model loss that encodes human preference rankings — far from textbook cross-entropy. The principle is identical though: define “wrong,” and minimize it.
3. Optimizers: The Correction Mechanism
The optimizer decides how weights are updated given the gradients. The industry standard today is Adam (Adaptive Moment Estimation).
Adam tracks two running averages: the mean gradient and the mean squared gradient. This lets it produce adaptive per-parameter learning rates. Parameters that receive large, noisy gradients get smaller updates. Parameters with small, consistent gradients get proportionally larger nudges.
The learning rate is the single most important hyperparameter in training. Too high and the optimizer overshoots the optimal weights. Too low and training crawls or stalls completely. The standard starting point is 1e-3 with Adam, then decay it over time as the model converges.
optimizer = tf.keras.optimizers.Adam(learning_rate=1e-3)
Key Insight: SGD with momentum is still widely used in computer vision. ResNets at Google are often trained with SGD. Adam dominates NLP and most general-purpose networks. Neither is universally “better.”
4. Validation: The Reality Check
Training loss tells you how the model performs on data it has seen. Validation loss tells you how it performs on data it has never seen. The gap between these two numbers is the most important diagnostic signal in the entire training process.
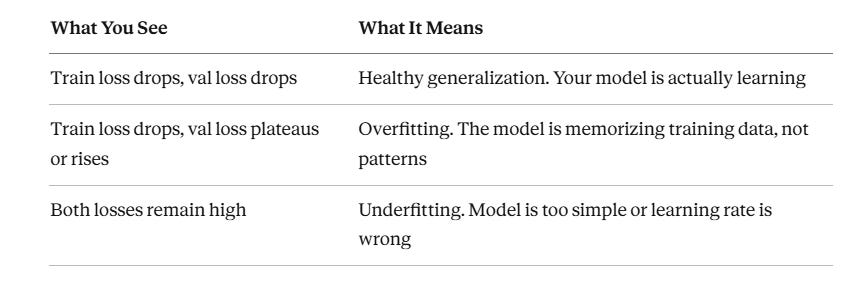
Your dataset splits into three groups: training (70–80%), validation (10–15%), and test (10–15%). The test set is held back entirely until final evaluation. It is your unbiased performance estimate for stakeholders, deployment gates, and audit trails. Touch it only once.
Component Architecture: How the Pipeline Fits Together
Raw Data
│
▼
[Data Pipeline] ──── batches ────▶ [model.fit()]
│
┌───────────┼───────────┐
▼ ▼ ▼
Forward Pass Loss Fn Optimizer
│ │ │
└───────────┴───────────┘
│
Weight Update
│
▼ (repeat per batch, per epoch)
│
[Validation Evaluation]
│
Metrics & Callbacks
│
[Saved Model Artifact]