Day 13: Derivatives and Their Applications in AI/ML

What We’ll Build Today
• Implement a gradient descent optimizer from scratch using derivatives • Create a simple neural network that learns to predict house prices • Build an interactive visualization showing how derivatives guide AI learning
Why This Matters: The Engine of AI Learning
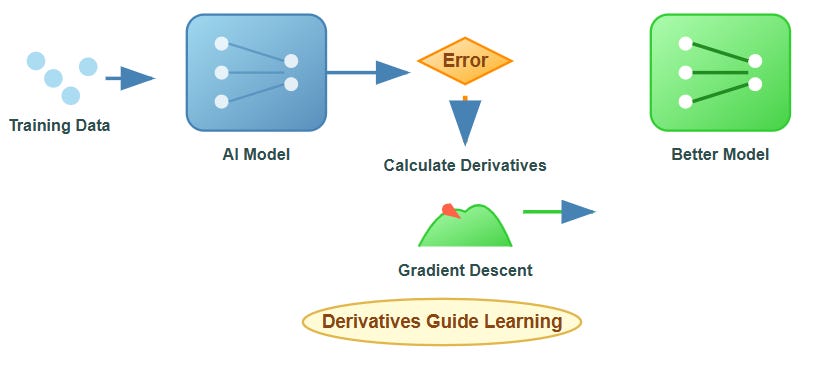
Think of derivatives as the GPS system for AI. Just as your phone’s GPS calculates the fastest route by analyzing the slope of different paths, AI systems use derivatives to find the optimal solution by following the steepest descent down an error landscape. Every time ChatGPT generates a response or a recommendation system suggests your next Netflix show, derivatives are working behind the scenes, guiding the AI toward better predictions.
In machine learning, we’re essentially playing a massive game of “hot and cold” where the AI tries to minimize its mistakes. Derivatives tell us exactly which direction leads to “colder” (lower error) and how big steps to take. Without derivatives, AI systems would be like ships without compasses, randomly wandering instead of systematically improving.
Core Concepts: The Mathematical Toolkit for AI
1. The Derivative as Rate of Change
A derivative measures how fast something changes. If you’re driving and your speedometer shows 60 mph, that’s the derivative of your position with respect to time. In AI, we use derivatives to measure how fast our error changes when we adjust our model’s parameters.
# If we have a simple error function: error = (prediction - actual)²
# The derivative tells us: “If I change my prediction by a tiny amount,
# how much will my error change?”
Think of it like adjusting the temperature on your oven. The derivative tells you whether turning the knob clockwise will make your cookies burn faster or cook more perfectly.
2. Gradient: The Multi-Dimensional Compass
In real AI systems, we’re not just adjusting one parameter like oven temperature—we might be adjusting millions. A gradient is like having a compass that points in multiple dimensions simultaneously, telling us the optimal direction to adjust all parameters at once.
Imagine you’re on a hiking trail in fog, trying to get to the lowest point in a valley. You can’t see far, but you can feel the slope under your feet. The gradient is like having super-sensitive feet that can detect the steepest downward slope in any direction.
3. The Chain Rule: Connecting the Dots
Modern AI systems are like complex assembly lines where the output of one process becomes the input of the next. The chain rule lets us trace how a small change at the beginning ripples through the entire system to affect the final result.
Think of it like a Rube Goldberg machine: if you push the first domino slightly harder, the chain rule calculates exactly how that affects the final ball dropping into the bucket. In neural networks, this lets us figure out how adjusting the connection strength between neurons affects the overall prediction accuracy.
4. Partial Derivatives: Isolating Variables
When you’re cooking, changing the oven temperature affects cooking time, but so does the altitude, humidity, and ingredients. Partial derivatives let us ask: “If I only change the temperature while keeping everything else constant, what happens to my cooking time?”
In AI, this helps us understand which parameters matter most for improving performance, allowing us to focus our optimization efforts where they’ll have the biggest impact.