

Day 128 — Activation Functions
The Decision Gates of Neural Networks
What We’re Building Today
Understand why activation functions exist and what happens without them
Explore the four activation functions powering every major AI system today — ReLU, Sigmoid, Tanh, and Softmax
Implement each from scratch in NumPy, then validate against PyTorch
Connect activation function choice to real production model architectures
Why This Matters
Yesterday you hit the wall: a perceptron can only draw straight lines. XOR is unsolvable. Every real-world problem — detecting cancer in an MRI, routing a self-driving car, ranking your Instagram feed — is non-linear by nature. Activation functions are the single mechanism that transforms a rigid linear machine into a universal function approximator. Without them, stacking 100 layers is mathematically identical to having one layer. Every neural network at Google, OpenAI, and Tesla runs on the four functions you’ll implement today. This is not academic warmup — this is the engine.
Core Concepts
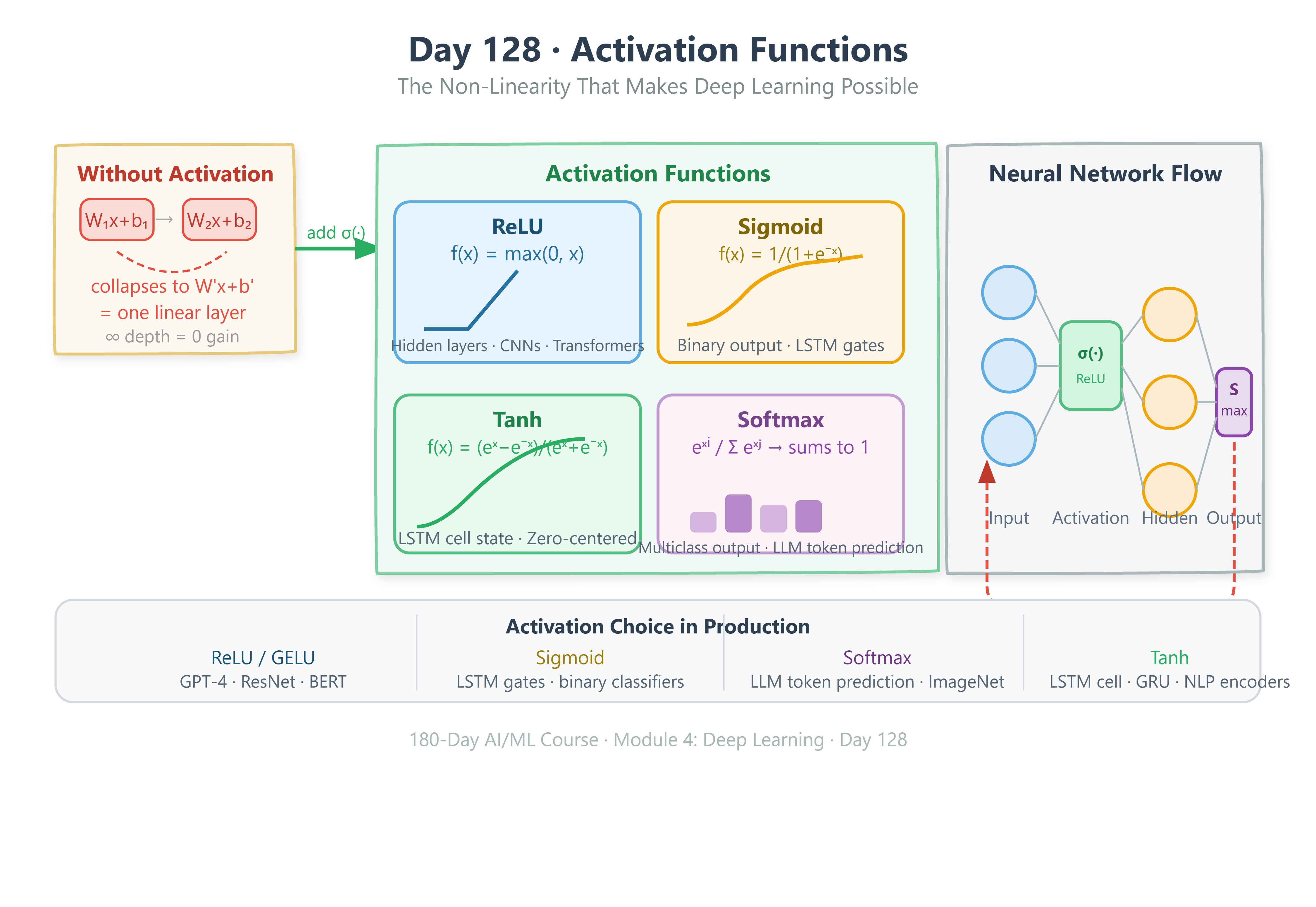
1. The Linear Trap — Why Stacking Doesn’t Help Without Activation
Picture a standard neuron: it takes inputs, multiplies them by weights, adds a bias, and produces an output. That operation is entirely linear — y = Wx + b. Stack two such layers: y = W2(W1x + b1) + b2. Expand it: y = (W2·W1)x + (W2·b1 + b2). This collapses back to y = W'x + b' — a single linear transformation. You could have a thousand layers and they’d all collapse into one. Activation functions break this collapse by applying a non-linear squeeze or gate between each layer, making the composition genuinely more expressive at every depth.
Layer 1 Layer 2 Without σ(·) With σ(·)
───────── ───────── ──────────── ──────────
W₁x + b₁ → W₂(·) + b₂ = W'x + b' truly deep
linear linear (one layer) (non-linear)
Preparing for a distributed systems interview?
→Download the free Interview Pack
→ Subscribe now to access source code repository - 200 + coding lessons
