Day 116: Hyperparameter Tuning Theory
180-Day AI/ML Course | Module 3: Unsupervised & Reinforcement Learning | Week 17–18: Advanced ML & Course Review
Today’s Agenda
What hyperparameters are and why they sit above the learning process itself
Three search strategies — Grid Search, Random Search, and Bayesian Optimization — and when each earns its place
Cross-validation during tuning and why naive evaluation destroys trustworthy benchmarks
Search space design — the craft of choosing what to tune and in what range
Production tuning patterns used by AutoML systems at Google, Meta, and OpenAI
Why This Matters
Yesterday, the bias-variance tradeoff showed you what can go wrong with a model — it either memorizes or generalizes poorly. Today’s lesson reveals the control panel that governs that tradeoff: hyperparameters. In production AI systems — recommendation engines, fraud pipelines, LLM fine-tuning jobs — hyperparameter tuning is not a one-time tweak you do before shipping. It is a continuous optimization loop that can mean the difference between a 72% AUC model and a 91% AUC model on identical data. No new data needed. No new architecture. Just tuning.
Core Concepts
1. Parameters vs. Hyperparameters: Two Entirely Different Animals
A parameter is what the model learns during training. Neural network weights, linear regression coefficients, decision tree split thresholds — the training algorithm adjusts these automatically by minimizing a loss function. You never set them by hand.
A hyperparameter is a configuration dial set before training begins. The learning rate of your optimizer, the number of trees in a Random Forest, the depth limit of a gradient boosting tree, the regularization strength in a Ridge regression — none of these are learned from data. The training algorithm does not know they exist. You are responsible for them.
Think of it this way: parameters are the musician’s finger movements during a performance (automatic, learned through practice). Hyperparameters are the choices you make before the concert — what tempo to rehearse at, how loud the hall is set, which room acoustics you record in. The musician adapts within those constraints, but the constraints themselves are yours to set.
This distinction matters enormously in system design. When an ML pipeline fails to meet accuracy SLAs in production, the first engineering question is almost never “is the model architecture wrong?” It is usually “are the hyperparameters calibrated to the production data distribution?”
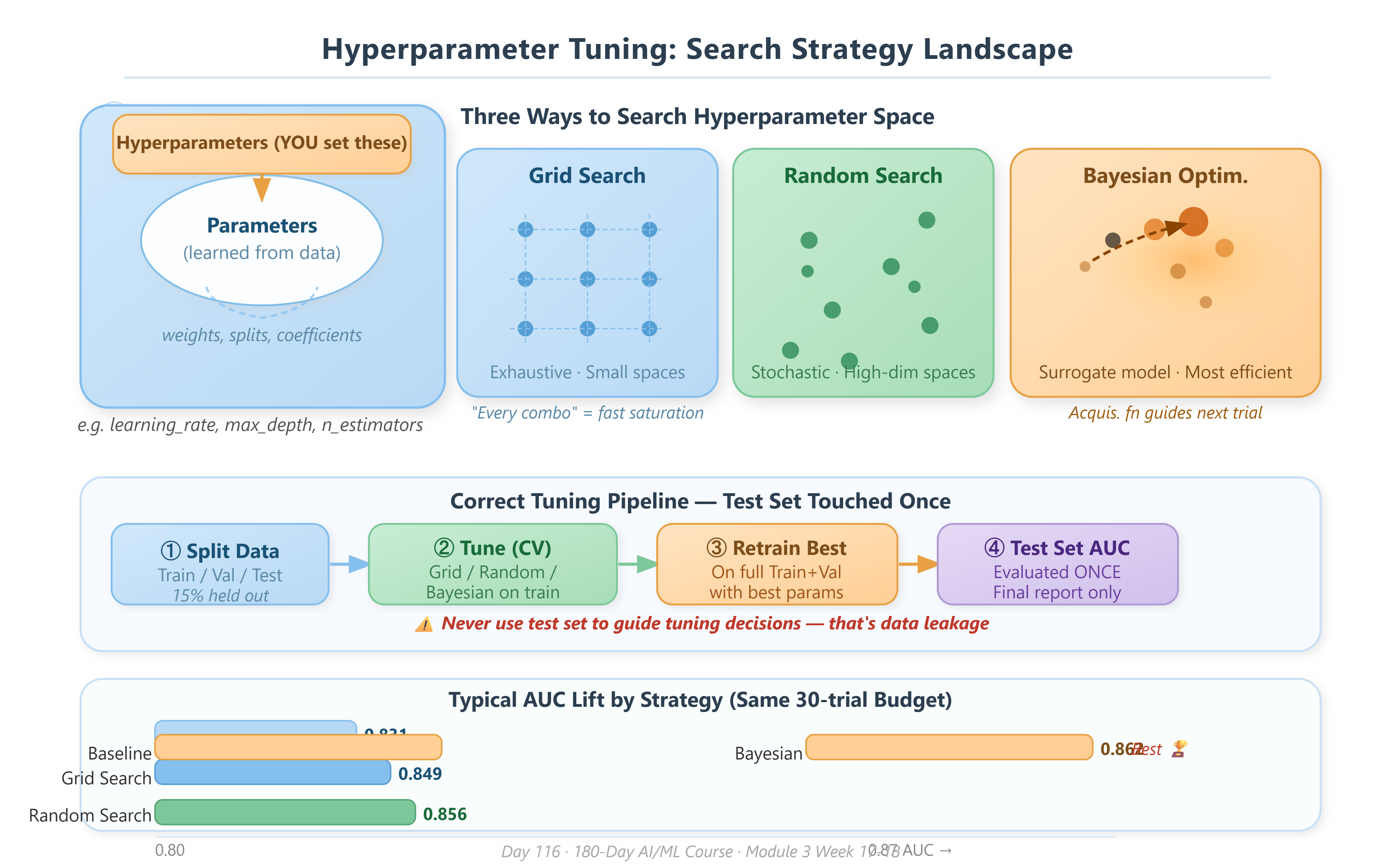
2. Grid Search: Exhaustive but Expensive
Grid Search defines a discrete grid of every hyperparameter combination and trains a model for each point. If you have three values for learning_rate, four values for max_depth, and three values for n_estimators, you run 3 × 4 × 3 = 36 training jobs.
The strength is completeness — within your grid, you miss nothing. The weakness is the curse of dimensionality: adding one more hyperparameter multiplies your compute by the number of values you test for it. For five hyperparameters with five values each, you run 5⁵ = 3,125 jobs. In production environments with expensive GPU training, Grid Search is only viable for small, well-understood search spaces.
3. Random Search: Surprisingly Better in High Dimensions
Random Search samples the hyperparameter space randomly for a fixed budget of trials. The 2012 Bergstra & Bengio paper proved that for most real-world problems — where a subset of hyperparameters dominates model performance — Random Search finds better configurations than Grid Search with the same compute budget.
The insight is geometric: Grid Search wastes resources sampling many values of unimportant hyperparameters in a regular pattern. Random Search, being irregular, automatically allocates more distinct values to every dimension. For high-dimensional search spaces (five or more hyperparameters), Random Search is the baseline you beat, not the baseline you start with.
4. Bayesian Optimization: Search That Learns from Itself
Bayesian Optimization builds a surrogate model — typically a Gaussian Process or Tree Parzen Estimator — that approximates the relationship between hyperparameter configurations and validation performance. After each trial, it updates this internal model and uses an acquisition function to decide which configuration to try next.
The acquisition function answers: “Given what I already know about this search space, where is the next trial most likely to improve my best result?” It balances exploitation (sampling near known good regions) with exploration (sampling in unexplored regions that might be even better).
This is the architecture behind Google’s Vizier, Meta’s Ax, and AWS SageMaker’s hyperparameter jobs. At scale, Bayesian Optimization typically finds configurations 3–10× better than Random Search within the same number of trials. For production ML systems where a single training run costs hours of GPU time, this efficiency multiplier directly translates to engineering velocity.
5. Cross-Validation and the Tuning Trap
Here is where students most commonly introduce silent bugs: evaluating your tuning on the test set.
The correct workflow is:
Split data into train, validation, and test sets at the start
Tune hyperparameters using only train + validation (via k-fold CV)
Report final performance on the test set once, at the end
If you use the test set to guide tuning decisions — even informally — you have committed data leakage. Your test set score is no longer an unbiased estimate of production performance. The model has effectively “seen” the test set through your decision-making. This is one of the most common root causes of models that perform excellently in evaluation but degrade sharply after deployment.